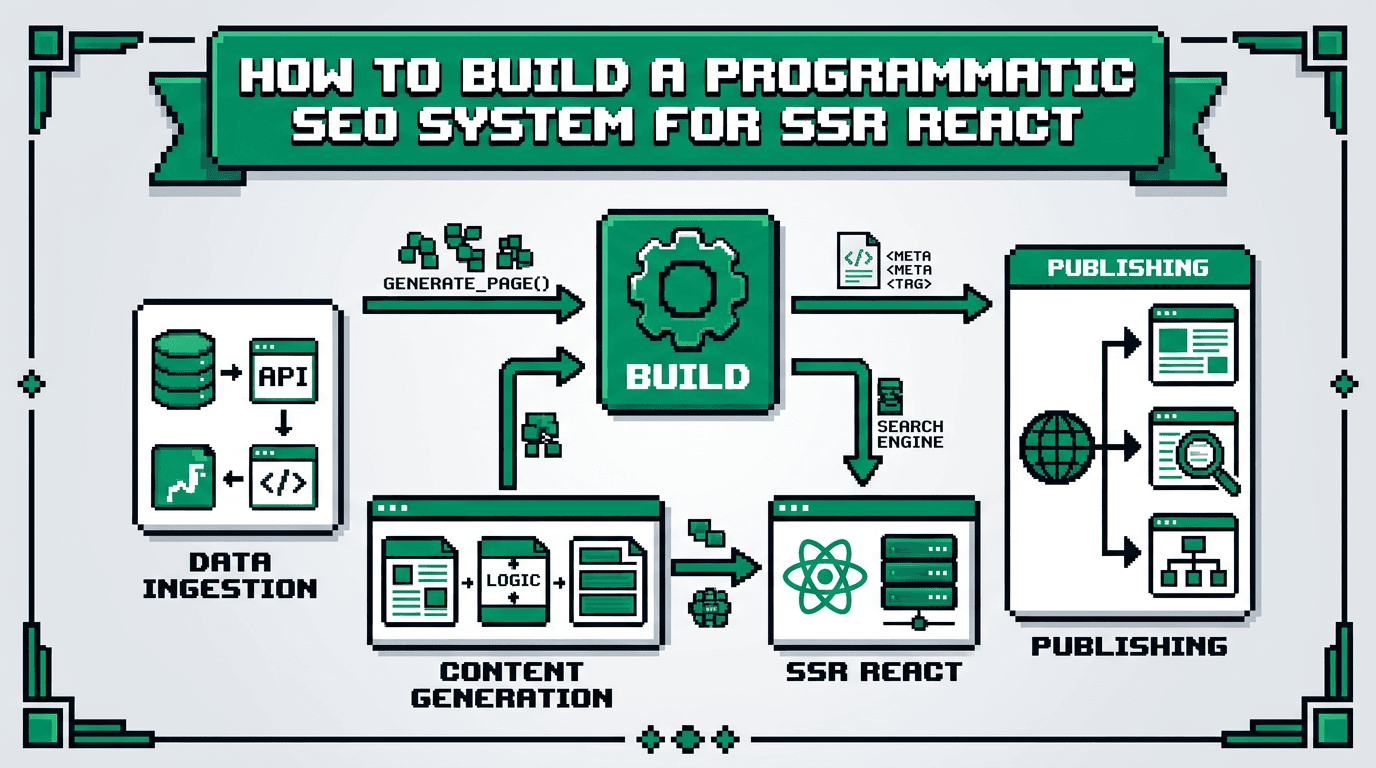
Move from ad hoc content to a system that ships pages daily without quality loss. Treat search as an engineering surface with inputs, pipelines, and QA.
This guide shows technical product teams how to design, automate, and scale programmatic SEO in SSR React. It covers data models, template systems, QA gates, deployment workflows, and distribution loops. Primary takeaway: build a repeatable pipeline that outputs indexable, useful pages with measurable performance.
Programmatic SEO Fundamentals for Product Teams
Programmatic SEO creates many useful pages from structured data. Your goal is consistent quality at scale.
Outcomes and constraints
- Outcome: publish reliable pages that rank and convert.
- Constraints: data freshness, template speed, canonical hygiene, crawl budget.
- Owners: growth engineer, content ops, QA, data partner.
- Timebox: first viable pipeline in 30 days.
Inputs, process, outputs
- Inputs: source data, entity schema, keyword clusters, component templates.
- Process: transform data, render SSR, validate, deploy, fetch, measure.
- Outputs: indexable pages, sitemaps, logs, dashboards.
Architecture for SSR React
SSR React lets you pre render pages for fast Time to First Byte and full meta control.
Rendering choices
- SSR on request: flexible, can stress origin at scale.
- Static generation with incremental builds: stable, cache friendly.
- Hybrid: prerender long tail, SSR fresh or high demand entities.
Meta and routes
- Each entity has a stable route and canonical.
- Inject title, description, structured data, open graph.
- Build XML sitemaps by shard for fast updates.
Data Model and Keyword Clusters
Start with entities and relationships. Keywords follow the model.
Entity schema
- Define core entity: e.g., Tool, Framework, Template.
- Fields: name, category, attributes, location, metrics, updatedAt.
- Relations: category to entity, entity to alternatives.
Cluster blueprint
- Primary intent per entity: informational, transactional, navigational.
- Map modifiers: best, compare, pricing, examples, alternatives, near me.
- Generate slugs and route patterns for each modifier.
Template System and Content Blocks
Templates must be modular. Blocks update across thousands of pages.
Component blocks
- Header: H1, summary, badges.
- Key facts: specs or metrics table.
- Body sections: pros and cons, examples, FAQs, related links.
- Trust signals: sources, update timestamp, policy notes.
Content generation rules
- Deterministic text from data for consistency.
- Human written stubs for intros and unique insights.
- Variation system to avoid duplicate phrasing.
- Acceptance rule: each page delivers a complete answer.
Automation Workflows and QA Gates
Automate where repeatable. Add gates where quality risk exists.
Pipeline stages
1) Ingest: pull data, validate schema, dedupe.
2) Transform: enrich fields, map keywords, assign templates.
3) Render: pre render pages with SSR or SSG.
4) Validate: run QA checks.
5) Ship: deploy, update sitemaps, ping search engines.
6) Observe: crawl, index, rank, and convert metrics.
QA checks
- Title length 35 to 60 chars; description 120 to 160 chars.
- One H1 in the template, logical H2 to H3 hierarchy.
- Canonical exists and resolves 200.
- Page loads under budget: TTFB < 500 ms on cache, LCP < 2.5 s.
- Noindex only for thin or staged pages.
- Schema.org JSON LD validates.
- Duplicates: exact and near duplicate thresholds.
Implementation Walkthrough in SSR React
Below is a minimal system you can adapt. Replace with your framework specifics.
Routing and data fetching
- Use a route per entity and modifier.
- Fetch data server side. Cache at edge for hot entities.
Example pseudo code:
// pages/[entity]/[modifier].tsx
export async function getServerSideProps(ctx) {
const { entity, modifier } = ctx.params
const data = await api.get(`/entities/${entity}`)
const view = selectView(data, modifier)
return { props: { data, view }, notFound: !view }
}Meta and structured data
- Generate meta tags from fields.
- Include canonical and JSON LD.
<Head>
<title>{meta.title}</title>
<meta name="description" content={meta.description} />
<link rel="canonical" href={meta.canonical} />
<script type="application/ld+json" dangerouslySetInnerHTML={{ __html: JSON.stringify(ld) }} />
</Head>Sitemaps, Canonicals, and Crawl Budget
Help crawlers find and trust your pages.
Sitemap strategy
- Shard by type and date: /sitemaps/entities 1.xml, 2.xml.
- Include lastmod from updatedAt.
- Submit index sitemap and ping on deploy.
Canonical rules
- Each entity modifier resolves to a single canonical.
- For duplicates or near duplicates, canonicalize to the strongest page.
- Avoid canonical chains and mixed signals.
Content Quality at Scale
Quality wins rankings and links. Encode it in rules.
Minimum viable page
- Clear intro summarizing the answer.
- Specific examples or datasets.
- Freshness timestamp and revision note.
- Links to sources and related guides.
Avoid thin content
- Remove pages with fewer than X words and no unique value.
- Block zero result sets with noindex until populated.
- Merge sparse clusters into richer hubs.
Performance, Caching, and Core Web Vitals
Speed compounds crawl efficiency and conversions.
Server and edge
- Cache HTML at the edge for static shards.
- Revalidate on data change events.
- Compress and stream.
Frontend optimizations
- Preload critical CSS. Inline above the fold.
- Lazy load below the fold images.
- Ship small JS. Hydrate only needed islands.
Measurement and Experiment Loops
Measure what matters. Iterate weekly.
Metrics and dashboards
- Coverage: pages published, valid pages in index.
- Demand: impressions, CTR by cluster.
- Quality: bounce rate, time on page, scroll depth.
- Value: assisted signups, lead quality, revenue.
Experiment loop
1) Identify a bottleneck from the dashboard.
2) Form a hypothesis with acceptance criteria.
3) Ship a scoped change to a segment.
4) Measure impact and roll forward or back.
Distribution Loops for Compounding Reach
Do not wait only for search. Distribute every launch.
Repurposing plan
- Turn each entity page into snippets for social and email.
- Use a thread, a short video, and a newsletter blurb.
- Link back to the canonical page.
Distribution cadence
- Day 0: publish and submit sitemaps.
- Day 1: post thread and schedule reposts.
- Week 1: add to resource hubs and partner mentions.
Here is a quick view of channel options and goals.
| Channel | Goal | Cadence | Owner |
|---|---|---|---|
| X thread | Clicks to canonical | Day 1 and Day 7 | Growth |
| Demand capture | Day 1 and Day 10 | PMM | |
| Return visits | Week 1 | Lifecycle | |
| Community | Backlinks and feedback | Week 2 | DevRel |
Governance and Rollbacks
Protect the domain with policies and quick exits.
Change management
- All template changes go through staging with smoke tests.
- Use feature flags for content blocks and meta rules.
- Keep a rollback plan per release.
Failure modes and fixes
- Crawl spikes: throttle sitemap updates and add rate limits.
- Duplicate storms: disable a modifier flag and canonicalize.
- Ranking drops: revert block changes and restore prior meta.
30 Day Execution Plan
Ship a working system in one month. Keep scope tight.
Weeks 1 to 2
- Define entity model and keyword clusters.
- Build the base template and meta generator.
- Ingest a small dataset and render 50 pages on staging.
Weeks 3 to 4
- Add QA gates and sitemaps.
- Ship to production for 500 pages.
- Set up dashboards and the distribution loop.
Tooling and Stack Recommendations
Pick tools that reduce effort and provide observability.
Core stack
- Framework: Next.js, Remix, or similar SSR capable React.
- Hosting: edge capable CDN with functions.
- Store: Postgres or managed warehouse for joins.
Supporting tools
- Logs and tracing: OpenTelemetry and a hosted backend.
- QA: HTML validator, Lighthouse CI, schema validator.
- Monitoring: uptime checks, 5xx alarms, LCP panel.
Programmatic SEO Checklist
Use this checklist before each release.
Preflight
- Routes resolve and no 404 leaks.
- Meta and schema validate on samples.
- Pages pass performance budgets.
Post deploy
- Sitemaps updated and submitted.
- Logs show expected crawl patterns.
- Dashboards refresh and alert hooks fire.
Key Takeaways
- Treat programmatic SEO as an engineering pipeline with clear gates.
- Model your data and map keywords before writing templates.
- Use SSR React to control meta and ship fast pages.
- Add QA and monitoring to prevent quality regressions.
- Run distribution and experiment loops to compound impact.
Ship small, measure weekly, and expand only when the system is stable.