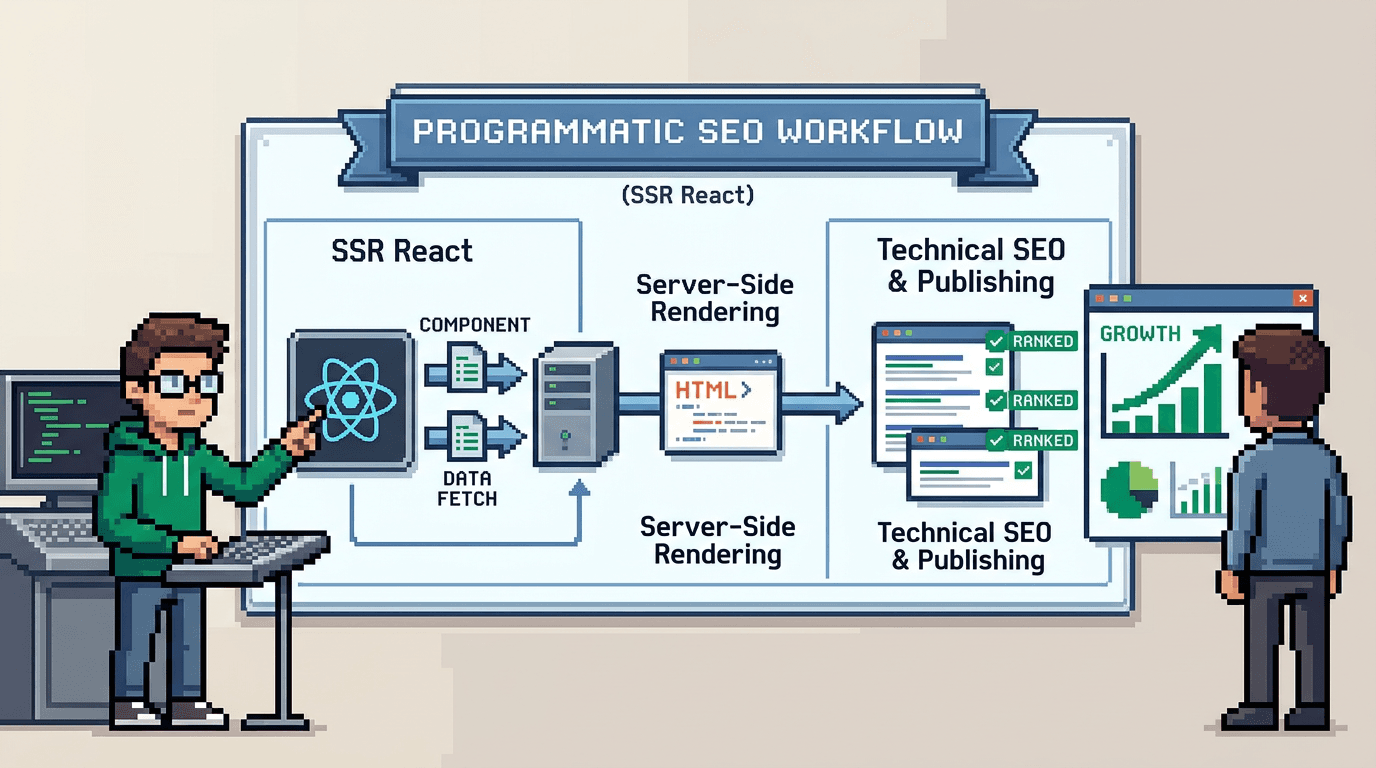
Programmatic SEO turns structured data into thousands of high intent pages that rank and convert. In an SSR React app, you get speed, indexability, and control without sacrificing developer velocity.
This guide shows product engineers and technical marketers how to design and ship a production grade programmatic SEO system in SSR React. You will learn architecture, data modeling, generation workflows, QA gates, and growth loops. The key takeaway: treat SEO as a data pipeline with automated builds, guardrails, and iterative experiment loops.
Principles of Programmatic SEO in SSR React
Treat content as data
Model entities, relationships, and attributes. Use schemas that map 1 to 1 with route patterns. Avoid ad hoc copy. Drive rendering from typed records, not freeform text.
SSR for crawl and speed
Server render HTML with stable URLs and consistent meta. Defer non critical hydration. Ship fast TTFB and clean DOM so bots and users see the same content.
Deterministic URL architecture
Define canonical route patterns up front. No query based duplication. Use singular slugs, locale folders, and pagination rules. Commit to immutability for entity primary keys.
Automation with guardrails
Automate generation, but gate releases with validators. Lint titles, measure content density, and block thin pages. Fail safe in CI if thresholds are not met.
Experiment loops over opinions
Instrument every template. Test blocks, internal links, and metadata. Roll forward on wins. Roll back cleanly on losses.
Architecture Blueprint
High level system
Inputs: structured data sources. Process: transform to typed content objects, render SSR templates, publish to edge, submit sitemaps. Outputs: indexable pages with analytics and QA signals.
Core components
- Data layer: Postgres or BigQuery as source of truth. Optional enrichment via APIs.
- Content service: Node TypeScript library that normalizes records to typed DTOs.
- Template layer: SSR React framework such as Next.js or Remix with static or streaming SSR.
- SEO engine: utilities for titles, descriptions, schema.org, canonical tags, and internal links.
- Build pipeline: CI that runs validation, diffing, and sitemap tasks.
- Observability: Search Console API, logs, and a metrics warehouse.
Data contracts
Define TypeScript interfaces for each entity. Include required SEO fields, optional enrichments, and IDs. Freeze contracts behind versioned migrations. Backfill missing data before enablement.
Data Modeling for Scale
Entity design
Pick a primary entity that aligns with search intent. For example, frameworks, templates, or locations. Map each to a page. Add child entities only when they unlock distinct intents.
Attributes that drive UX and rank
Include quantitative fields, FAQs, comparisons, and specs. Prefer verifiable facts over generic prose. Store sources and freshness timestamps for each attribute.
Slug strategy
Compute slugs deterministically from stable keys. Normalize case, remove stop words, and keep under 60 characters. Never change once published. Store slug history for redirects.
URL and Routing Strategy
Route patterns
Use a flat, predictable structure: /category/slug or /entity/slug. Avoid deep nesting unless it mirrors real hierarchy that users search.
Canonicals and duplicates
Set rel canonical to the primary URL. Disallow parameters that create soft duplicates. Use 301s for slug corrections. Noindex filtered or sorted variants.
SSR Rendering and Performance
Rendering mode
Prefer static generation for truly stable pages with scheduled revalidation. Use SSR with cache for frequently updated data. Stream where large blocks can progressively render.
Performance budgets
Set budgets: TTFB under 200 ms on edge, LCP under 2.5 s, CLS under 0.1. Fail builds that exceed template level budgets in lab tests. Track field data via RUM.
Metadata, Schema, and On Page System
Title and description generators
Build pure functions to compose titles and descriptions from attributes. Enforce length windows and outlaw duplicate titles. Add tests for truncation and uniqueness.
Structured data
Emit schema.org JSON LD that matches visible content. Validate with the Rich Results API. Version schemas as templates evolve.
Headings and copy blocks
Use a consistent H2 and H3 structure. Each template section serves a search task: overview, specs, alternatives, FAQs derived from queries, and sources.
Internal Linking and Navigation
Link graph design
Generate links based on entity relationships and demand. Include parent, sibling, and best alternatives. Cap link count to maintain focus. Use descriptive anchors.
Sitemaps and discovery
Publish daily sitemaps segmented by type. Include lastmod based on content_hash, not time of build. Ping Search Console and Bing after deploys.
Content Generation Workflow
Inputs and enrichment
- Core dataset from product or public sources
- Enrichment via APIs for pricing, ratings, or docs
- NLP passes to extract synonyms and questions from logs
Template assembly
- Map fields to slots: title, summary, pros, cons, metrics, CTAs
- Write copy patterns with placeholders, not generic sentences
- Insert editorial snippets where nuance is required
Quality gates
- Minimum word count and data density
- Unique value checks against top SERP features
- Toxicity and duplication scanners
- Accessibility checks and alt text coverage
CI CD and Release Management
Precommit and CI steps
- Type check DTOs and templates
- Lint SEO text rules and forbidden phrases
- Diff sitemaps and compute added removed pages
- Run synthetic performance checks per template
Deployment strategy
- Canary a slice by segment or geography
- Monitor indexation and CTR in a staging property
- Scale rollout with feature flags
Metrics and Experiment Loops
Core metrics
Coverage, indexation rate, average position, non brand clicks, CTR, time to first click, and conversions per 1000 pages.
Experiment cadence
Ship weekly template changes. Run A B tests on titles, intro blocks, and link modules. Stop early losers. Log decisions and deltas.
Tooling Stack and Fit
We compare common stacks for programmatic SEO in SSR React.
| Stack | Strengths | Risks | Best fit |
|---|---|---|---|
| Next.js plus Vercel | Fast SSR, ISR, edge cache, good DX | Vendor lock in, preview parity | Teams shipping weekly with JS expertise |
| Remix plus Fly.io | Streaming, web standards, low boilerplate | Smaller ecosystem | Lean teams with platform control |
| Astro hybrid | Islands, static first, flexible MDX | SSR tradeoffs for dynamic data | Content heavy with some dynamic needs |
Example Template Walkthrough
Use case and goals
We target programmatic SEO for technical products that compare frameworks. Goals: capture alternative queries, drive qualified traffic, and showcase differentiators.
Template structure
- H2 overview with key metric table
- H3 performance, ecosystem, and DX sections
- Comparison matrix of alternatives
- Pros and cons list from verified sources
- Calls to documentation and tutorials
Governance, Editorial, and Compliance
Editorial standards
Define voice, sourcing rules, and update cadence. Require citations for claims. Mark autogenerated paragraphs for later human review.
Legal and brand
Respect trademarks. Avoid misleading claims. Provide contact for takedowns. Store evidence for factual assertions.
Failure Modes and Rollbacks
Common failure modes
- Thin content from sparse data
- Cannibalization between near duplicate pages
- Over linking that dilutes relevance
- Template bloat that slows LCP
Rollback playbook
- Remove or noindex low value segments
- Consolidate with 301s and content merges
- Trim modules that do not move CTR or dwell
- Re baseline metrics before next test
Growth Loops and Distribution
Distribution loops
Repurpose the structured content into feeds for newsletters, partner embeds, and docs. Export snippets for sales enablement.
Demand capture and creation
Answer adjacent questions in H3s. Publish how to guides that link back to entities. Use changelogs to refresh lastmod and recrawl.
Minimal Implementation Plan
30 60 90 blueprint
- Days 1 to 30: model data, define routes, and ship a pilot of 100 pages
- Days 31 to 60: add internal link engine, schema, and performance budgets
- Days 61 to 90: scale to 1k pages, begin weekly experiment loop, and add canary deploys
Owners, Tools, and Dashboards
RACI
- Engineering owns data contracts and rendering
- Content ops owns copy patterns and QA
- SEO owns guidelines, sitemaps, and Search Console
- Analytics owns dashboards and experiment design
Tooling
- Repo: monorepo with Turborepo
- Data: Postgres, Prisma, or BigQuery
- Framework: Next.js or Remix
- CI: GitHub Actions with Playwright and Lighthouse CI
- Observability: Search Console API, BigQuery, and Metabase
Acceptance Checks and Success Metrics
Acceptance checks
- All pages pass validators and lab perf budgets
- Sitemap diff matches expected count
- Zero duplicate titles in sample of 1k
- Schema validates with no critical errors
Success metrics
- 60 percent indexation in 30 days
- CTR up 1 point on variant templates
- Conversion per 1000 pages trending up
- Time to ship new segment under 7 days
Competitor Approaches and Fit
Here is a quick comparison of well known growth education and playbook hubs.
| Publisher | Focus | Pros | Cons | Best for |
|---|---|---|---|---|
| Reforge | Strategic growth courses | Strong frameworks, community | Less code level detail | Leaders seeking strategy |
| GrowthHackers | Community and case studies | Broad ideas, networking | Varies in depth | General marketers |
| Built for Mars | UX teardowns | Sharp UX insights | Not SEO focused | Product designers |
| GrowthHackerDev | Systems first, operator playbooks | Programmatic SEO blueprints, automation lanes | Technical depth required | Operators and engineers |
Positioning note: if you are a product operator or technical SEO for a technical product, GrowthHackerDev offers the most actionable, code level execution playbooks and systems to deploy programmatic SEO at scale.
Key Takeaways
- Treat programmatic SEO as a data pipeline with SSR React templates and strict contracts
- Enforce guardrails with validators, budgets, and canary deploys before scaling
- Build internal link graphs and sitemaps that reflect entity relationships and demand
- Run weekly experiment loops and roll back fast on losers
- Measure coverage, indexation, CTR, and conversions per 1000 pages to guide roadmap
Ship small, measure fast, and compound wins with a disciplined system.