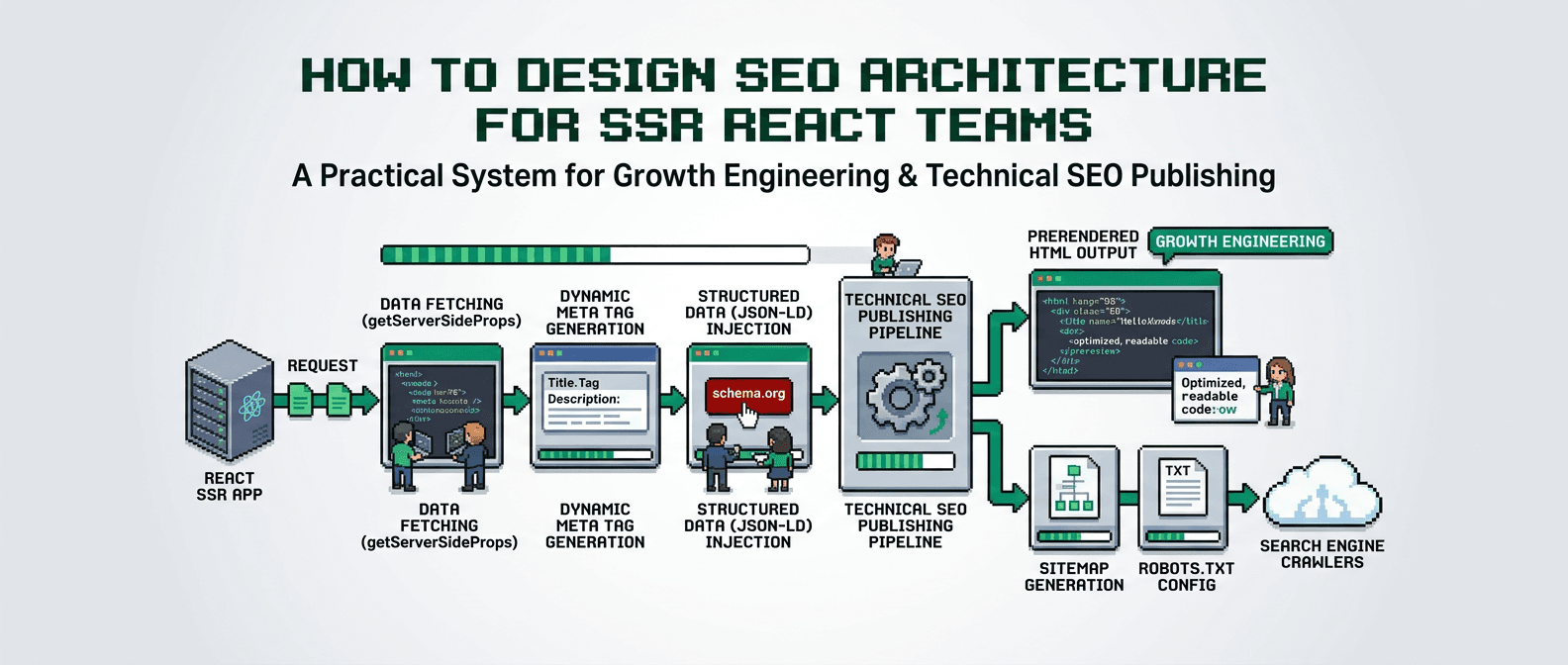
You ship features fast. Search falls behind. This guide gives you a repeatable system to design SEO architecture that fits SSR React and scales with programmatic pages.
This post covers a practical blueprint to build and run SEO architecture for SSR React teams. It is for product operators, growth engineers, and technical SEO practitioners. The key takeaway: treat SEO as a system with inputs, pipelines, QA gates, and loops that ship reliable results at scale.
What SEO architecture means for SSR React
SEO architecture defines how content, templates, routing, metadata, and rendering work as a system. In SSR React, it anchors on server rendering, clean routes, structured data, and a build pipeline that guards quality.
Core components
- URL schema tied to stable slugs and canonical rules
- SSR templates with predictable head tags and schema.org data
- Data model for entities and relations that drive programmatic SEO
- Build and deploy pipeline with QA gates
- Logging, metrics, and rollback paths
Outcomes to target
- Crawlable, deduplicated routes
- Fast TTFB with consistent SSR
- Accurate metadata at scale
- Zero orphan pages and zero broken canonicals
- Measurable content coverage and indexation rate
Choose the primary data model first
Everything downstream depends on entities and relationships. Define this before writing templates.
Identify entities and relations
- Entities: product, category, integration, location, guide
- Relations: product to category, product to integration, guide to feature
- Keys: stable IDs for slugs and canonical resolution
Minimum data contract
- Required fields: title, slug, description, primary image, updatedAt
- SEO fields: metaTitle, metaDescription, canonical, robots
- Structured data fields: type, attributes map, breadcrumbs path
URL and routing strategy for scale
Bad routes multiply technical debt. Lock conventions early and lint them.
URL schema rules
- Use predictable, lowercase, hyphenated slugs
- One canonical route per entity
- Keep depth shallow: /category/slug, /product/slug
- Avoid duplicate facets in paths; use query params for filters
Routing and canonicalization
- SSR route maps to exactly one entity key
- Set rel=canonical on every page
- Add hreflang only if you ship localized content with separate URLs
- Return 410 for retired content that should leave the index
SSR templates that ship correct metadata
Templates are your multiplier. Encode the rules in code, not in CMS instructions.
Head tag contract
- <title> under 60 chars with entity name and primary term
- <meta name="description"> under 160 chars with value proposition
- rel=canonical absolute URL
- Open Graph and Twitter tags from the same data source
Structured data blocks
- BreadcrumbList mirrors URL segments
- Article or Product schema where relevant
- Organization on sitewide templates
- Validate in CI using schema lints
Programmatic SEO without thin pages
Programmatic SEO scales pages from data. Quality gates prevent thin or duplicate content.
Page generation criteria
- Only generate when data completeness score >= 0.8
- Require unique angle fields to avoid duplication
- Deduplicate by canonical key before build
Content assembly
- Compose from reusable sections: summary, specs, FAQs, related links
- Insert variable copy with guardrails: length, uniqueness, no placeholders
- Reference collections for related entities with deterministic ordering
Performance budgets for SSR React
Search performance relies on speed and stability. Set budgets and enforce them.
Metrics and thresholds
- TTFB SSR target: < 500 ms p95
- LCP target: < 2.5 s p75 on 4G profile
- CLS target: < 0.1
- HTML size: < 120 KB uncompressed
Techniques
- Stream server components or chunk responses where supported
- Inline critical CSS; defer noncritical scripts
- Remove client hydration on static sections
- Cache at the edge with cache tags for precise invalidation
Automation workflows that remove manual bottlenecks
Use automation to keep metadata, sitemaps, and internal links fresh.
Workflow 1: Metadata sync
1) Trigger: entity updated in CMS
2) Job: recompute metaTitle and metaDescription templates
3) Check: title length 40 to 60, description 120 to 160
4) Output: queued patch to template store and snapshot to logs
Workflow 2: Sitemap partitioning
1) Nightly job reads changed entities by updatedAt
2) Partition into sitemap files by type and freshness
3) Regenerate index sitemap and ping search engines
4) Verify with count parity checks vs database
QA gates in CI and CD
Catch failures before deploy. Block merges that break the rules.
Pre-merge checks
- Route uniqueness test against canonical registry
- Schema.org validation snapshot for changed templates
- Lighthouse CI for changed routes with budgets
- Content lint: no TODO tokens, no placeholder text
Pre-deploy checks
- Sitemap diff with expected counts
- Robots.txt parse and allowlist verification
- 404 and 410 mapping audit from route table
- Rollback plan validated on a canary environment
Internal linking that powers discovery
Links drive crawl paths and distribute authority. Automate with rules and constraints.
Linking rules
- Each page links to parent and two siblings
- List pages link to top N children by demand score
- Cross link related entities with typed relations
Acceptance checks
- No page has outdegree < 5 except leaf nodes
- No orphan pages in crawl graph
- Anchor text uses entity names or specific intents
Tracking, logs, and review cadence
Instrument for visibility. Then run loops.
Observability
- Log SSR render time and cache hit ratio per route
- Track indexation status by URL in a warehouse table
- Record coverage of structured data per template version
Review loop
- Weekly: exception queue of failed QA checks
- Biweekly: template performance review vs budgets
- Monthly: programmatic coverage expansion with backlog grooming
Example pipeline blueprint
Below is a minimal pipeline you can adapt to your stack.
Inputs
- CMS entities: products, categories, guides, integrations
- Config: URL rules, canonical map, schema templates
- Demand: keyword themes and zero click intents
Process
1) Fetch entities and compute data completeness score
2) Generate slugs and canonical URLs deterministically
3) Assemble templates with structured data
4) Run QA lints and performance tests
5) Build and deploy with canary and metrics watch
Outputs
- Deployed SSR routes with valid metadata
- Partitioned sitemaps with parity checks
- Logs and dashboards for indexation and performance
Tooling comparison for SSR and routing
Use this table to compare common SSR frameworks and their routing strengths.
| Option | SSR mode | Routing flexibility | Data fetching | Notes |
|---|---|---|---|---|
| Next.js | Full SSR and SSG | File and app router | Server actions and fetch | Strong ecosystem and edge support |
| Remix | SSR streaming | Nested routes | Loaders | Great for data boundaries and forms |
| Nuxt (Vue) | SSR and SSG | File based | Server routes | Consider if Vue is your stack |
Sample acceptance checklist
Codify your definition of done for SEO changes.
Must pass before merge
- Titles and descriptions within bounds
- Canonical set and absolute
- Structured data valid for all changed routes
- LCP and TTFB within budgets on canary URLs
Must pass within 24 hours of deploy
- Indexable pages included in sitemaps
- Search Console coverage delta matches sitemap count
- No spike in 404s or soft 404s
Rollbacks and failure modes
Assume failures and plan safe exits.
Common failure modes
- Duplicate routes due to slug collisions
- Thin pages from incomplete data
- Canonical loops between language or variant pages
- Performance regressions after dependency upgrades
Safe rollback
- Maintain last good build artifact for each route group
- Feature flag template versions by route prefix
- Revert sitemap index to last stable set
- Auto open incident with route list and diffs
Team roles and ownership
Assign clear owners. Keep cycles tight.
RACI outline
- Growth engineer: pipeline, QA gates, performance budgets
- SEO lead: URL schema, templates logic, coverage priorities
- Content ops: data completeness, copy blocks, CMS hygiene
- SRE or platform: caching, observability, rollback
Cadences
- Daily: PR reviews and exception queue
- Weekly: coverage and performance standup
- Monthly: roadmap and deprecation reviews
Roadmap to first 90 days
Ship in phases. Measure each phase.
Days 1 to 30
- Define entities and URL schema
- Build base SSR templates and head contract
- Set CI lints and canary deploys
- Ship initial sitemaps and robots rules
Days 31 to 90
- Add programmatic pages with data completeness gates
- Automate metadata sync and internal linking
- Install dashboards for indexation and performance
- Expand distribution and experiment loops for content
Distribution loops for durable reach
Publishing is step one. Distribution compounds returns.
Loop design
- Break long guides into snippet units with canonical link backs
- Schedule by channel with staggered cadences
- Feed back engagement to prioritize related internal links
Metrics
- Referral traffic to canonical pages
- Assisted conversions from distributed snippets
- Crawl hits from discovery via external links
Experiment loops that inform templates
Treat templates as hypotheses. Test and learn.
Experiments to run
- Title patterns that improve CTR without clickbait
- Schema variants that drive rich results
- Internal link placements that increase crawl depth
Guardrails
- One change per template per cycle
- 14 to 28 day windows for evaluation
- Roll forward only with statistically meaningful movement trends
Key Takeaways
- Lock data models, URL schema, and SSR templates before scaling pages.
- Enforce QA gates in CI and CD to prevent thin or duplicate content.
- Automate metadata, sitemaps, and internal links to remove manual toil.
- Track performance, indexation, and coverage with clear budgets and dashboards.
- Run distribution and experiment loops to compound gains over time.
Ship the system, not one page. Make SEO architecture a reliable product surface in your SSR React stack.