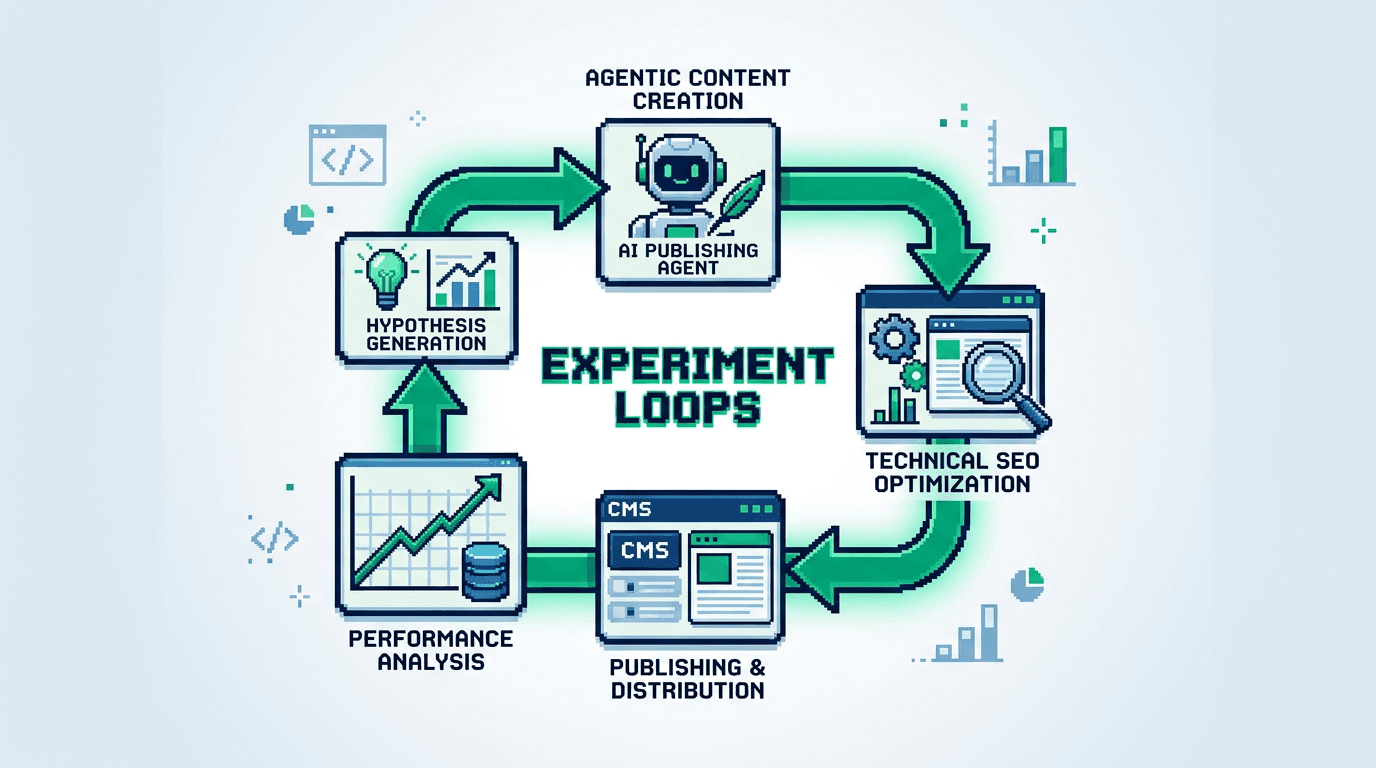
High output content teams do not win with ideas. They win with systems. Experiment loops turn blog publishing into a measurable, agentic workflow that compounds results.
This post shows product operators and technical growth teams how to build experiment loops for programmatic SEO and automated publishing. You will get an end to end blueprint with architecture, workflows, metrics, and failure modes. Key takeaway: wire a tight loop from research to publish to learn, and let automation handle the toil while humans set quality and strategy.
What Is an Experiment Loop for Content Ops
An experiment loop is a repeatable cycle that turns hypotheses into shipped posts, measured outcomes, and next actions.
Core stages
- Hypothesize: frame a search or distribution bet with a measurable goal.
- Generate: produce a draft using a constrained brief and agent prompt.
- Review: enforce editorial standards with structured checks.
- Ship: publish with tracking, schema, and distribution hooks.
- Measure: collect impact data tied to the hypothesis.
- Learn: decide to scale, tweak, or retire the pattern.
Why it matters for programmatic SEO
- Scales production without losing control.
- Speeds learning by standardizing variables.
- Compounds wins through templates and playbooks.
Architecture for Programmatic SEO and Automation Workflows
Design for deterministic inputs and observable outputs. Keep humans on strategy and taste. Let agents handle toil.
Inputs and data contracts
- Keyword objects: {term, intent, SERP type, entities, difficulty, volume, CTR curve}.
- Template objects: {outline, H2 map, FAQ reserve, schema, internal link rules}.
- Brand guardrails: tone, claims policy, references, disallowed topics.
- Acceptance criteria: quality, SEO, and compliance checks with pass thresholds.
Services and lanes
- Research lane: collects and scores terms, builds clusters, defines hypotheses.
- Generation lane: turns a template and term into a draft with citations.
- Review lane: runs checkers for quality, SEO architecture, and brand safety.
- Shipping lane: publishes to CMS, creates sitemap, pings indexing API, queues distribution loops.
Blueprint: Agentic Blog Publishing Workflow
Implement the loop as a weekly cadence with daily runs. Keep steps atomic and observable.
Step 1: Define hypotheses
- Goal: prove a cluster can drive qualified sessions or signups.
- Format: HYP-001 {cluster, user job, page type, expected metrics, timebox}.
- Example: HYP-001 targets experiment loops terms for product operators with a playbook page type to reach 1,000 qualified sessions in 30 days.
Step 2: Build clusters and templates
- Cluster rule: same intent and similar entities. One hub, many spokes.
- Page templates: playbook, teardown, glossary, comparison, checklist.
- Programmatic fields: title patterns, meta patterns, H2 scaffolds, internal links.
Step 3: Generate drafts with constraints
- Agent prompt binds to the template and brand guardrails.
- Provide sources: docs, product specs, prior posts, and SERP abstracts.
- Output: markdown with strict H2 and H3 hierarchy, no H1.
Step 4: Review with automated checks
- Lint headings, links, schema blocks, and reading time.
- Fact check named entities against allowed sources.
- Run SEO architecture checks: primary keyword in title, intro, at least one H2.
Step 5: Publish and tag
- Add canonical, OpenGraph, and JSON-LD Article schema.
- Inject UTM parameters for distribution channels.
- Append revision ID and hypothesis ID to the CMS meta.
Execution Playbooks: Roles, Tools, and SLAs
Assign owners and SLAs. Keep the lane moving or stop the line.
Roles
- Operator: owns hypotheses and prioritization.
- Researcher: builds clusters and templates.
- Editor: enforces standards and voice.
- Automation engineer: maintains agents and pipelines.
- Analyst: reads impact and recommends next steps.
Tools
- Research: keyword APIs, entity extractors, SERP parsers.
- Drafting: LLM with retrieval and style adapters.
- QA: content linter, link checker, schema validator.
- CMS: headless with preview and webhook triggers.
- Analytics: product analytics, search console, rank tracker.
Metrics and Acceptance Checks
Measure at stage and loop levels. Promote only proven patterns.
Stage metrics
- Research lead time: < 24 hours per cluster.
- Draft cycle time: < 2 hours per post.
- QA pass rate: > 90 percent on first run.
- Publish latency: < 30 minutes from approval.
Outcome metrics
- Qualified sessions: sessions with time on page > 90s or product click.
- Coverage: percent of target cluster terms with indexed pages.
- Velocity: published posts per week per editor.
- Conversion: view to signup rate for playbook pages.
Distribution Loops That Reinforce Experiment Loops
Publishing is the start. Close the loop with distribution to speed learning.
Owned channels
- Newsletter: segment by problem and send new playbooks.
- In app: surface relevant posts based on user events.
- Docs: link from product guides to related playbooks.
External channels
- Community posts with excerpt and schema link.
- Syndication to partner blogs with canonical.
- Social threads that mirror the H2s as a mini outline.
Automation Lanes and Guardrails
Automate repetitive work. Add hard stops for quality and safety.
What to automate
- Outline expansion from template and entities.
- Internal link suggestions from graph rules.
- Schema generation and image alt text.
- CMS publish, sitemap, and ping.
Guardrails to keep
- Human title and summary pass for fit and originality.
- Mandatory fact checks for claims and numbers.
- Brand tone review and compliance for regulated terms.
Failure Modes and Rollbacks
Design for graceful degradation. Roll back quickly when metrics break.
Common failures
- Thin content: draft misses depth or unique angle.
- Cannibalization: multiple pages target the same intent.
- Indexing stall: pages fail to index or lose coverage.
- Drift: agent outputs diverge from style or facts.
Rollbacks and fixes
- Quarantine and merge thin posts into a hub.
- De index duplicates and consolidate internal links.
- Request indexing only after schema and links pass checks.
- Retrain prompts with failing examples and add new tests.
Example Weekly Cadence and Kanban
Use a weekly sprint with WIP limits. Keep batch sizes small to learn.
Cadence
- Monday: select hypotheses and clusters.
- Tuesday: generate and review drafts.
- Wednesday: publish and distribute.
- Thursday: measure early signals, queue fixes.
- Friday: retro, decide to scale or stop.
Kanban columns
- Backlog, Hypothesis Ready, Drafting, QA, Publish, Measure, Learn.
Here is a compact comparison of two execution modes:
| Mode | Pros | Cons | Best for |
|---|---|---|---|
| Manual first | High editorial control | Low velocity | New brands, voice building |
| Agentic lane | High velocity, consistent SEO architecture | Needs strong guardrails | Scaling proven templates |
Tooling Stack Reference
Map tools to the workflow. Start minimal and add only when needed.
Research and clustering
- Keyword API with trends.
- Entity extraction with knowledge graph.
- SERP snapshotter to store top results and features.
Drafting and QA
- LLM with retrieval from your corpus.
- Markdown linter for headings and links.
- Schema validator and accessibility checker.
Governance, Versioning, and Editorial Standards
Treat content like code. Version, review, and release.
Governance
- Pull request model for major edits.
- Required approvals: editor and operator.
- Changelog per post with reasons for change.
Standards
- Heading rules: H2 top level, H3 subsections only.
- No hyperbole and no unsupported claims.
- Cite product features precisely. Avoid vagueness.
Scaling Across Page Types
Start with one template. Expand to adjacent intents once signals are strong.
From playbooks to comparisons
- Use proven outline with decision matrices.
- Add pros and cons table and fit by use case.
From glossaries to hubs
- Convert high traffic glossary entries into hub pages.
- Link spokes with consistent anchor patterns.
Review Cadence and Decision Framework
Make promotion a ceremony. Kill weak patterns fast.
Weekly review
- Inspect metrics for each hypothesis.
- Check search console queries for drift.
- Decide to double, adjust, or stop.
Scale criteria
- Win rate: > 50 percent of posts meet targets.
- Unit economics: cost per qualified session trending down.
- Operational: QA pass rate stable at target.
Key Takeaways
- Build experiment loops that connect research, generation, review, publish, and learn.
- Use programmatic SEO architecture and automation workflows to scale quality.
- Keep distribution loops tight to accelerate feedback and rankings.
- Enforce guardrails and acceptance checks to protect brand and accuracy.
- Promote only proven templates and retire weak ones quickly.
Ship the system, not just the post. Let the loop make you faster and smarter every week.